
Is SQL DISTINCT good (or bad) when you need to remove duplicates in results?
Some say it’s good and add DISTINCT when duplicates appear. Some say it’s bad and suggest using GROUP BY without an aggregate function. Others say DISTINCT and GROUP BY are the same when you need to remove duplicates.
This post will dive into the details to get correct answers. So, eventually, you will use the best keyword based on the need. Let’s begin.
A brief reminder about the basics of the SQL SELECT DISTINCT statement
Before we dive deeper, let’s recall what the SQL SELECT DISTINCT statement is. A database table can include duplicate values for many reasons, but we may want to get the unique values only. In this case, SELECT DISTINCT comes handy. This DISTINCT clause makes the SELECT statement fetch unique records only.
The syntax of the statement is simple:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Here, the WHERE condition is optional.
The statement applies both to a single column and multiple columns. The syntax of this statement applied to multiple columns is as follows:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Note that the scenario of querying several columns will suggest using the combination of values in all columns defined by the statement to determine the uniqueness.
And now, let’s explore the practical usage and catches of applying the SELECT DISTINCT statement.
How SQL DISTINCT Works to Remove Duplicates
Getting answers is not so hard to find. SQL Server provided us with execution plans to see how a query will be processed to give us the needed results.
The following section focuses on the execution plan when using DISTINCT. You need to press Ctrl-M in SQL Server Management Studio before executing the queries below. Or, click Include Actual Execution Plan from the toolbar.
Query Plans in SQL DISTINCT
Let’s begin by comparing 2 queries. The first will not use DISTINCT, and the second query will.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Here’s the execution plan:
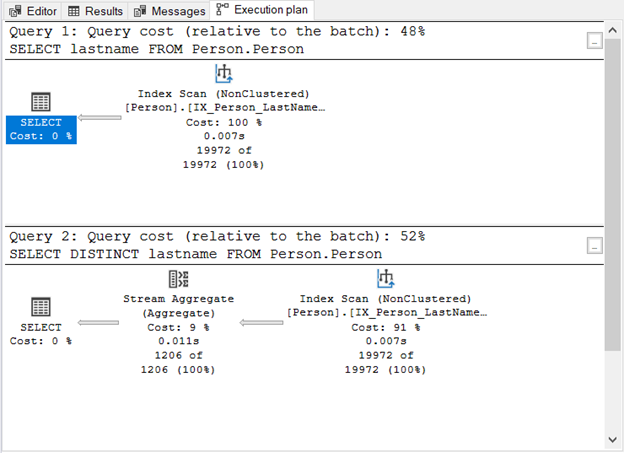
What did Figure 1 show us?
- Without the DISTINCT keyword, the query is simple.
- An extra step appears after adding DISTINCT.
- The query cost of using DISTINCT is higher than without it.
- Both have Index Scan operators. This is understandable because there’s no specific WHERE clause in our queries.
- The extra step, the Stream Aggregate operator, is used to remove the duplicates.
The number of logical reads is the same (107) if you check the STATISTICS IO. Yet, the number of records is vastly different. 19,972 rows are returned by the first query. Meanwhile, 1,206 rows are returned by the second query.
Hence, you cannot add DISTINCT anytime you want. But if you need unique values, this is a necessary overhead.
There are operators used to output unique values. Let’s examine some of them.
STREAM AGGREGATE
This is the operator you saw in Figure 1. It accepts a single input and outputs an aggregated result. In Figure 1, the input comes from the Index Scan operator. However, Stream Aggregate needs a sorted input.
As you can see in Figure 1, it uses the IX_Person_LastName_FirstName_MiddleName, a non-unique index on names. Since the index already sorts the records by name, the Stream Aggregate accepts the input. Without the index, the query optimizer may opt to use an extra Sort operator in the plan. And that will be more expensive. Or, it can use a Hash Match.
HASH MATCH (AGGREGATE)
Another operator used by DISTINCT is Hash Match. This operator is used for joins and aggregations.
When using DISTINCT, Hash Match aggregates the results to produce unique values. Here’s one example.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
And here’s the execution plan:
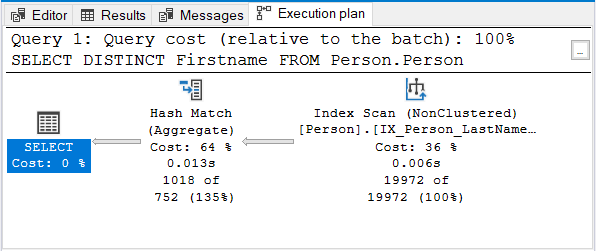
But why not Stream Aggregate?
Notice that the same name index is used. That index sorts with Lastname first. So, a Firstname only query will become unsorted.
Hash Match (Aggregate) is the next logical choice to remove the duplicates.
HASH MATCH (FLOW DISTINCT)
The Hash Match (Aggregate) is a blocking operator. Thus, it won’t produce the output it has processed the entire input stream. If we restrict the number of rows (like using TOP with DISTINCT), it will produce a unique output as soon as those rows are available. That’s what Hash Match (Flow Distinct) is all about.
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
The query uses TOP 100 along with DISTINCT. Here’s the execution plan:
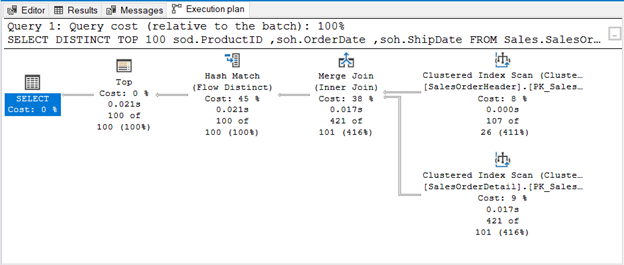
WHEN THERE’S NO OPERATOR TO REMOVE DUPLICATES
Yup. This can happen. Consider the example below.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Then, check the execution plan:
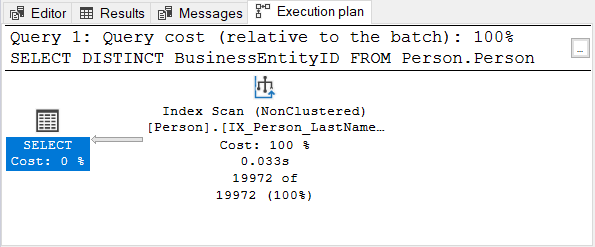
The BusinessEntityID column is the primary key. Since that column is already unique, there is no use in applying DISTINCT. Try removing DISTINCT from the SELECT statement – the execution plan is the same as in Figure 4.
The same is true when using DISTINCT on columns with a unique index.
SQL DISTINCT Works on ALL Columns in the SELECT List
So far, we have only used 1 column in our examples. However, DISTINCT works on ALL columns you specify in the SELECT list.
Here’s an example. This query will make sure that the values of all 3 columns will be unique.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Notice the first few rows in the result set in Figure 5.
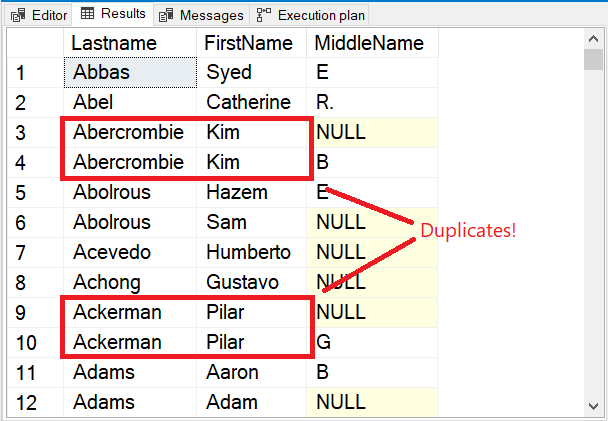
The first few rows are all unique. The DISTINCT keyword made sure that the Middlename column is also considered. Notice the 2 names boxed in red. Considering the Lastname and Firstname only will make them duplicates. But adding Middlename to the mix changed everything.
What if you want to get unique first and last names but include the middle name in the result?
You have 2 options:
- Add a WHERE clause to remove NULL middle names. This will remove all names with a NULL middle name.
- Or, add a GROUP BY clause on Lastname and Firstname columns. Then, use the MIN aggregate function on the Middlename column. This will get 1 middle name with the same last and first names.
SQL DISTINCT vs. GROUP BY
When using GROUP BY without an aggregate function, it acts like DISTINCT. How do we know? One way to find out is to use an example.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Run them and check out the execution plan. Is it like the screenshot below?
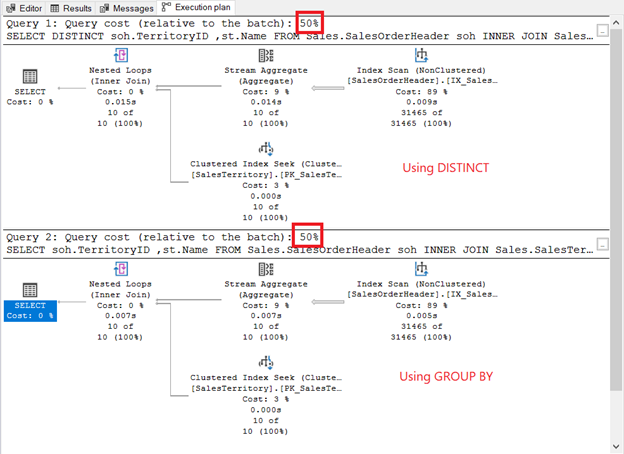
How do they compare?
- They have the same plan operators and sequence.
- The operator cost of each and the query costs are the same.
If you check the QueryPlanHash properties of the 2 SELECT operators, they are the same. Therefore, the query optimizer used the same process to return the same results.
In the end, we can’t say that using GROUP BY is better than DISTINCT in returning unique values. You can prove this by using the above examples to replace DISTINCT with GROUP BY.
It is now a matter of preference which will you use. I prefer DISTINCT. It explicitly tells the intent in the query – to produce unique results. And for me, GROUP BY is for grouping results using an aggregate function. That intent is also clear and consistent with the keyword itself. I don’t know if someone else will maintain my queries one day. So, the code should be clear.
But that’s not the end of the story.
When SQL DISTINCT is Not the Same as GROUP BY
I just expressed my opinion, and then this?
It’s true. They won’t be the same all the time. Consider this example.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Though the result set is unsorted, the rows are the same as in the previous example. The only difference is the use of a subquery:
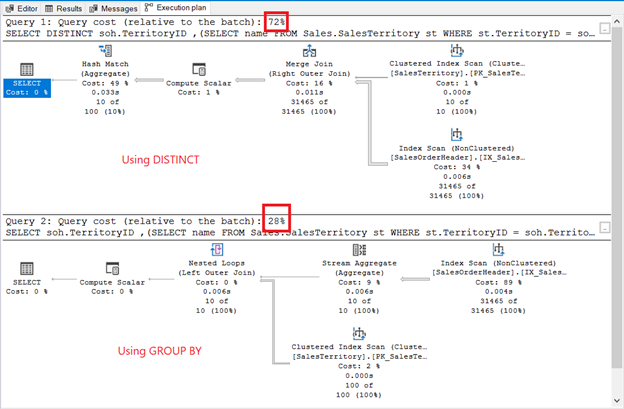
The differences are obvious: operators, query cost, overall plan. This time, GROUP BY wins with only 28% query cost. But here’s the thing.
The aim is to show you that they can be different. That’s all. This is by no means a recommendation. Using a join has a better execution plan (see Figure 6 again).
The Bottomline
Here’s what we have learned so far:
- DISTINCT adds a plan operator to remove duplicates.
- DISTINCT and GROUP BY without an aggregate function result in the same plan. In short, they are the same most of the time.
- Sometimes, DISTINCT and GROUP BY can have different plans when a subquery is involved in the SELECT list.
So, is SQL DISTINCT good or bad in removing duplicates in results?
The results say that it’s good. It’s not better or worse than GROUP BY because the plans are the same. But it’s a good habit to check the execution plan. Think of optimization from the start. That way, if you stumble with any differences in DISTINCT and GROUP BY, you will spot them.
Besides, the modern tools make this task much simpler. For instance, a popular product dbForge SQL Complete from Devart has a specific feature that calculates values in the aggregate functions in the ready result set of the SSMS result grid. The DISTINCT values are also present there.
Like the post? Then, please spread the word by sharing it on your favorite social media platforms.
Related Articles for More Information
- SQL GROUP BY: 3 Easy Tips to Group Results Like a Pro
- SQL INSERT INTO SELECT: 5 Easy Ways to Handle Duplicates
- What are SQL Aggregate Functions? (Easy Tips for Newbies)
- SQL Query Optimization: 5 Core Facts to Boost Queries








